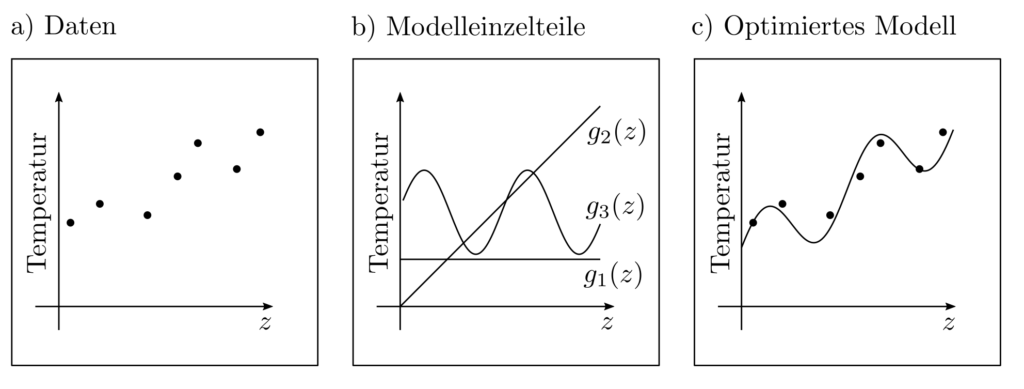
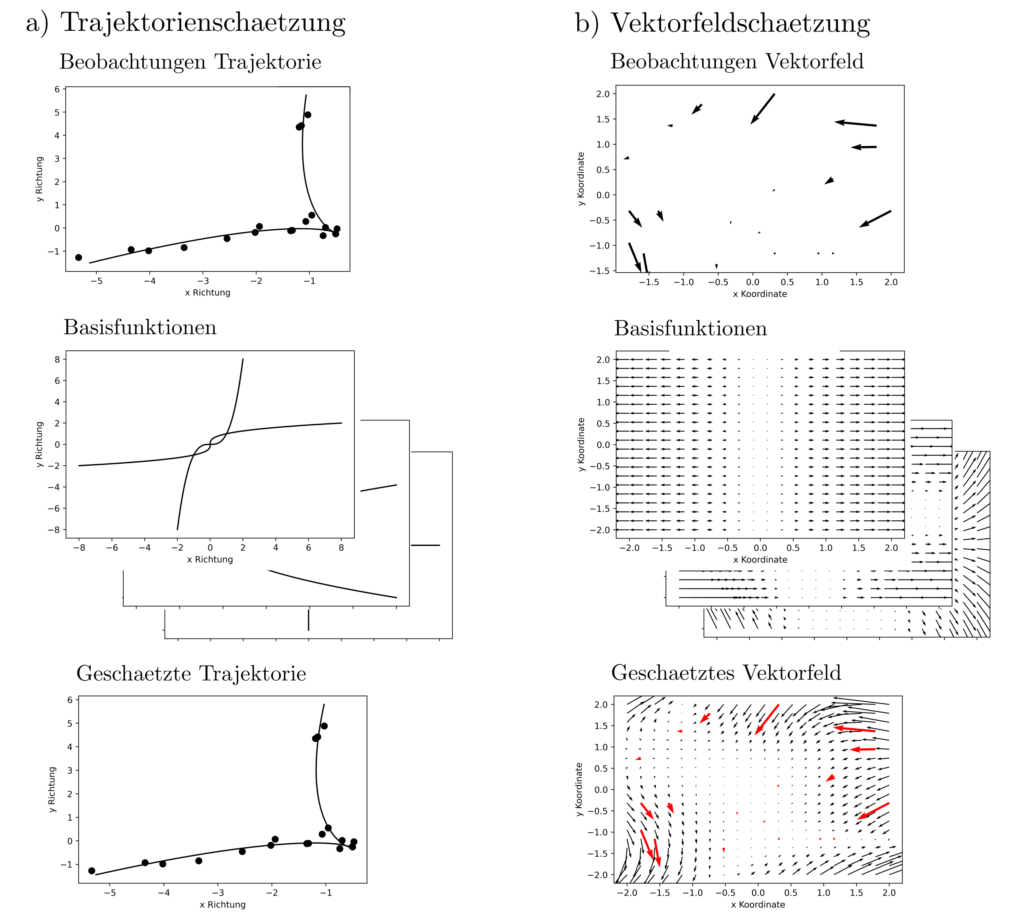
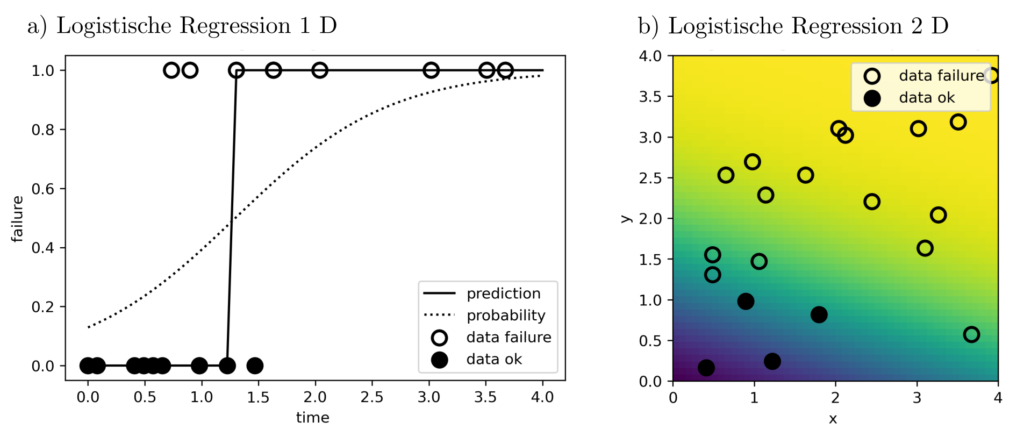
Die bisherigen Formulierungen beinhalten quadratische Zielfunktionen der Form \(sum_{k=1}^n \|l_k‑g(x,z_k)\|_2^2\) und sind demnach least-squares Probleme. Eine Minimierung dieser Zielfunktionen ist sinnvoll, wenn die Modellklasse \(g(x,z)=\sum_{k=1}^m x_mg_m(z) \) für irgendeine bestimmte Wahl von \(x\) die Daten vollständig erklären kann is auf (standard)normalverteile Residuen \(\epsilon\). Dann gilt
$$ l_k=g(x,z_k)+\epsilon_k \Leftrightarrow \epsilon_k= l_k‑g(x,z_k). $$
Die Wahrscheinlichkeiten der Residuen \(\epsilon_1, …, \epsilon_n\) sind dann \(p(\epsilon_k)= (2 \sqrt{\pi})^{-1} \exp\left( — \frac{1}{2} \epsilon_k^2\right)\). Die Wahrscheinlichkeit des Eintretens aller Residuen \(\epsilon_1, …, \epsilon_n\) gemeinsam ist
$$ p(\epsilon_1, …, \epsilon_n)=\prod_{k=1}^np(\epsilon_k) = (2^n \pi^{n/2})^{-1} \exp\left( -\frac{1}{2} \sum_{k=1}^n \epsilon_k^2 \right)$$ für statistisch unabhängige Residuen \(\epsilon_k \coprod \epsilon_j, k \neq j\). Eine wahl von \(x\) so, dass all die Residuen \(\epsilon_1= l_1‑g(x,z_1), …, \epsilon_n=l_n‑g(x,z_n)\) möglichst wahrscheinlich sind, führt auf
$$ \max_x p(\epsilon_1, …, \epsilon_n) \Leftrightarrow \min_x \sum_{k=1}^n \left(l_k‑g(x,z_k)\right)^2. $$
Die bisherigen Minimierungsprobleme lassen sich demnach schreiben als Wahrscheinichkeitsmaximierende Schätzer für den Erwartungswert von Daten \(l_k=g(x,z_k)+\epsilon_k\) unter der Annahme von unkorrelliertem, normalverteiltem Rauschen \(\epsilon_k\).