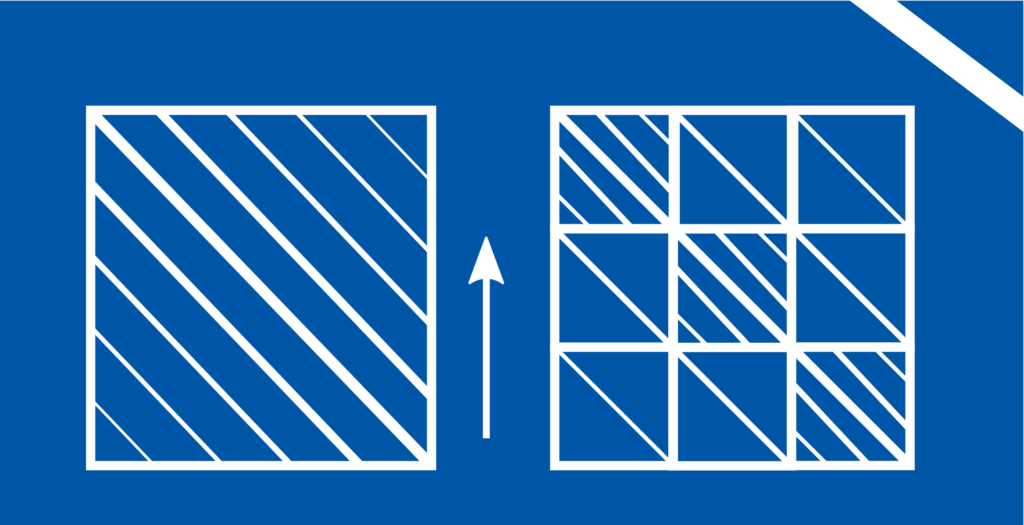
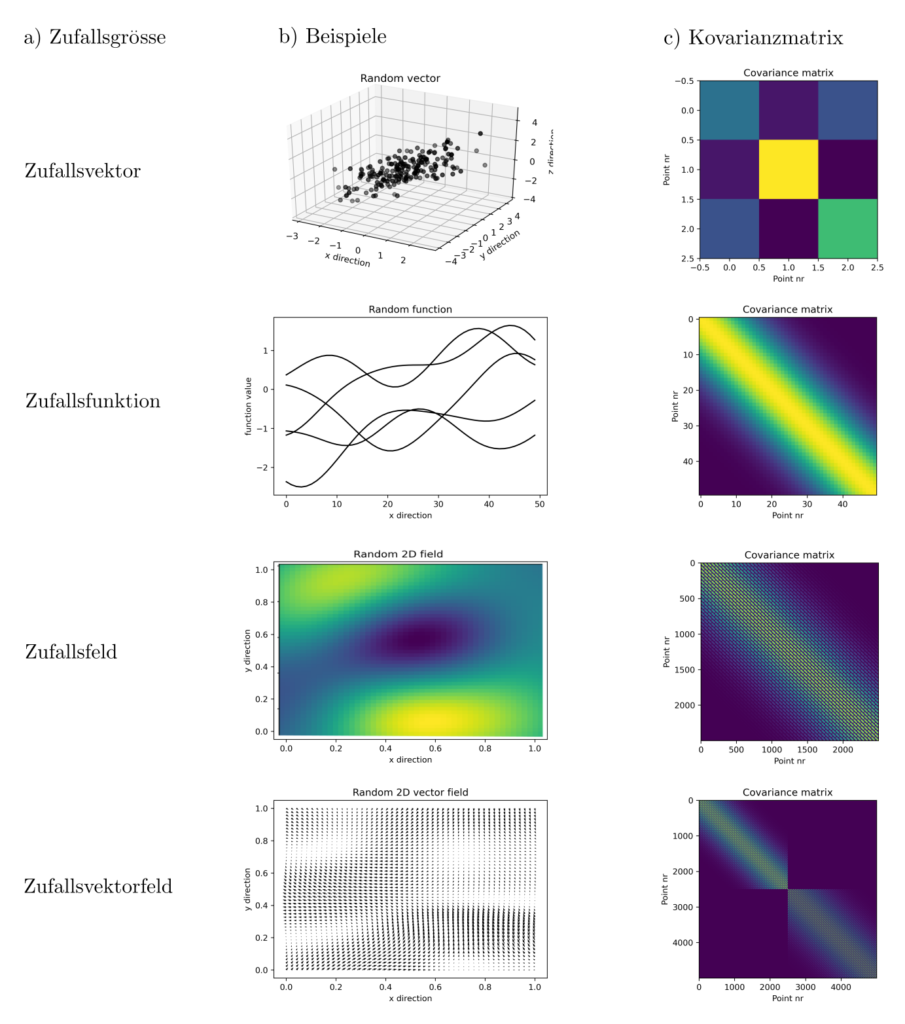
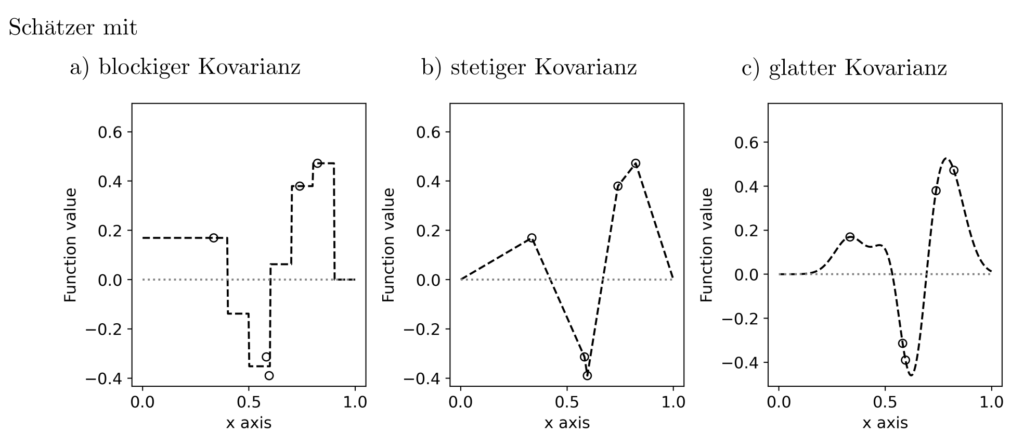
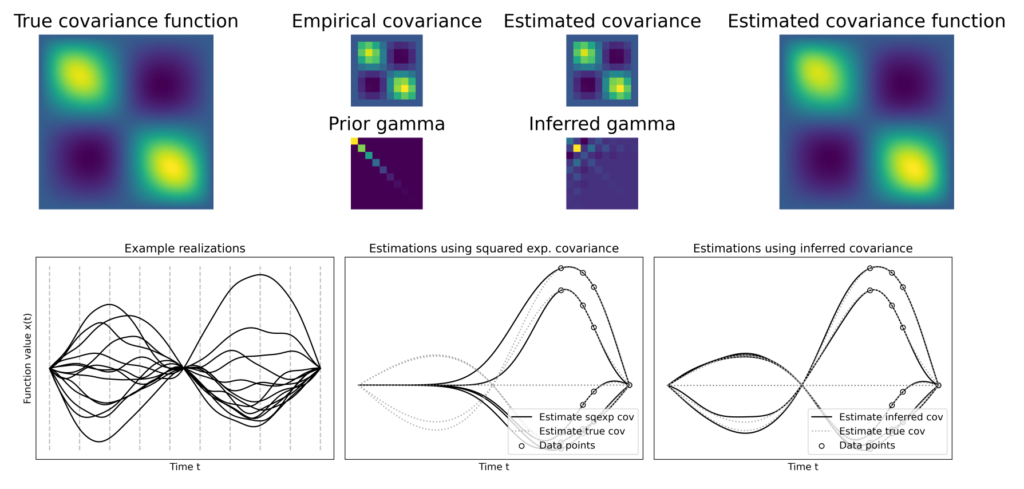
Nimmt man an, \(K(z_1,z_2)\) sei ein Quadrat \(B^TB = \int_Z B(z_1,z)B(z,z_2)dz\) normalverteilert zufälliger Funktionen \(B\), dann ist \(\gamma\) ungefähr Wishart verteilt. Mit \(p(l|\gamma)\) der bedingten Wahrscheinlichkeit von Beobachtungen \(l\) gegeben die Kovarianzfunktion in Abhängigkeit von \(\gamma\) sowie \(p(\gamma)\) der Wahrscheinlichkeit von \(\gamma\) gilt nach Bayes-theorem
$$p(\gamma|l) = c p(l|\gamma)p(\gamma) ~~~~~~ c \text{ eine Konstante}.$$
Dabei ist \(p(\gamma|l)\) die bedingte Wahrscheinlichkeit von \(\gamma\), wenn \(l\) beobachtet wurde. Maximierung der Wahrscheinlichkeit ist gleichbedeutend mit Minimierung von \(-\log p(\gamma|l)=-\log p(l|\gamma)-\log p(\gamma)\).
Das Optimierungsproblem lautet
$$ \begin{align} \min_{\gamma} ~~~& \log \det C_{\gamma} + \operatorname{tr} (SC_{\gamma}^+)+ r\left[ — \log \det \gamma + \operatorname{tr}(\Lambda^+\gamma)\right] \\ \text{s.t.}
~~~& A \gamma =b \\ ~~~& \gamma \succeq 0 \end{align}$$
wobei \(S\) die empirische Kovarianzmatrix der Daten \(l\), \(C_{\gamma}\) die mit Hilfe von \(\gamma\) rekonstruierte Kovarianzmatrix, \(C_{\gamma}^+\) deren Pseudeinverse und \(\Lambda\) eine Matrix ist, die a‑priori Annahmen über \(\gamma\) codiert. Die Regularisierungskonstante \(r\) gewichtet Vorwissen und Daten gegeneinander und \(A \gamma = b\) sind lineare Bedingungen für \(\gamma\). Sie repräsentieren definitives Wissen über der Korrelationsstruktur zugrundeliegende Zusammenhänge. Mit den Informationen über erste und zweite Ableitungen der Zielfunktion ergibt sich das numerische Schema [2, p. 194]
$$ \begin{align} \gamma &= \gamma +\Delta \gamma ‑A^T(A\gamma A^T)^+A\Delta \gamma \\ \Delta \gamma & = \frac{1}{1+r} \left[ (r‑1)\gamma +S_{\psi} — r\gamma \Lambda^+\gamma\right] \end{align}$$
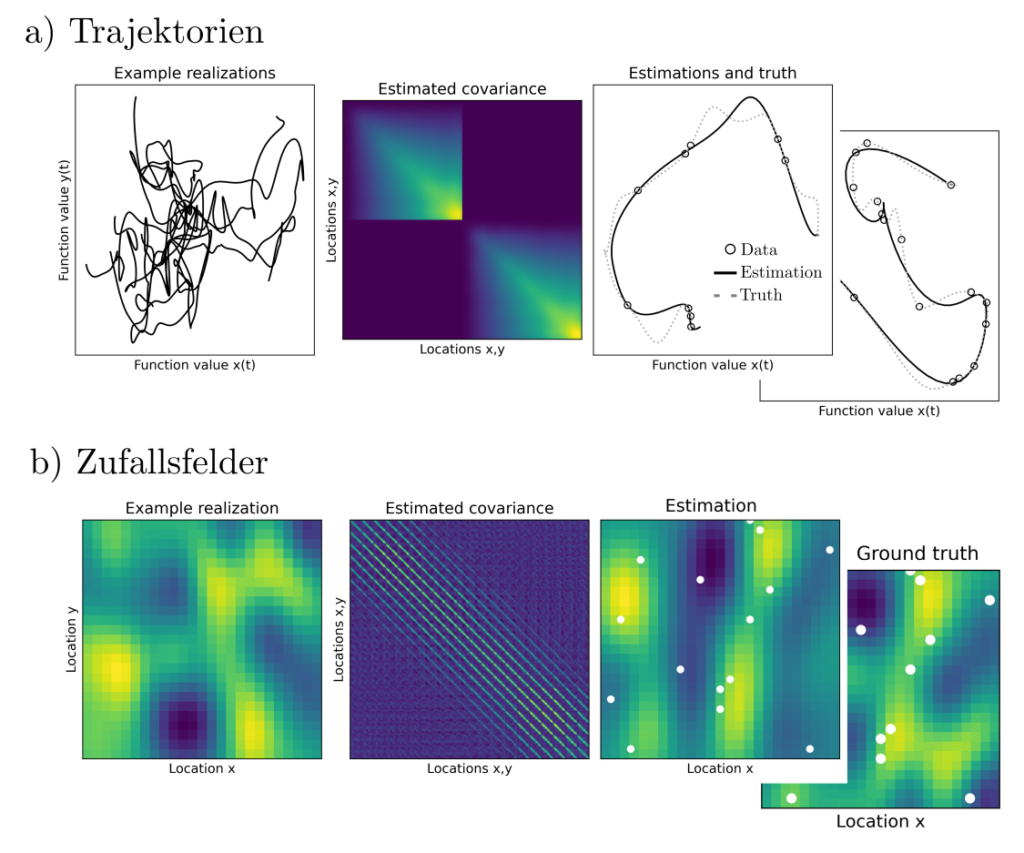
wobei \(S_{\psi}\) eine transformierte Variante der empirischen Kovarianzmatrix ist. Werden die iterationen über \(\gamma\) numerisch stabilisiert und bis zur Konvergenz ausgeführt, dann ist das Resultat eine mit Hilfe von \(\gamma\) konstruierte Kovarianzfunktion \( K(z_1,z_2)\). Sie sagt für alle möglichen Positionen \(z_1, z_2\) Korrelationen vorher, die maximal konsistent sind mit den punktuellen Beobachtungen \(l\) und den Vorannahmen.